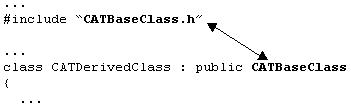
#include to include the header file of the base class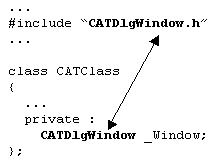
#include to include the header file of a class when
an instance of this class is used as a data member
Rules and Standards |
CAA V5 C++ Coding RulesRules, hints and tips to write C++ code |
| Technical Article |
AbstractThis article gives you a set of rules and advice to better write your C++ code, to correctly deal with object lifecycle, and to appropriately use the CAA V5 Object Modeler. |
This set of rules deal with the C++ entities you will use.
Create a separate header file for each class, interface, structure, global enumumeration, global function, and macro, and put in this file only the declaration of this entity. This file must have the same name than the entity. For example, the CATBaseUnknown class header file is CATBaseUnknown.h.
This is the appropriate means to protect code from a multiple inclusion of your header file. Do this as follows, for example for the CATBaseUnknown class:
#ifndef CATBaseUnknown_h #define CATBaseUnknown_h ... // Put here the #include statements, ... // forward class declarations, and the class stuff #endif |
#include JudiciouslyWhen you create a header file, always ask you the following question for each file you include: "Do I really need to include this file, or is a forward declaration enough?" Here is the answer to this question:
|
Use #include to include the header file of the base class |
|
Use #include to include the header file of a class when
an instance of this class is used as a data member |
|
Use the class forward declaration when a reference of, a value, or a pointer to a class is used as a method returned value or parameter, or if a pointer to a class is used as a data member |
For any included file, check that you actually use the class, the enum, the
macro, the type defined by a typedef, or a parameter among the set
defined by #define contained in the file, or otherwise remove it.
Do not include C++ header files, such as stream.h or iostream.h, if they are useless, since they can include static data that is in any case allocated whatever the way you use these files.
Never copy and paste sets of #include statements from another
file. This is the worst you can do, since it's then more difficult to sort
useful and useless files. If you include useless header files, your code grows
and the time required to manage the module dependency impacts and to build it
increases.
namespace StatementsComply to the naming rules [1] instead.
Do not use threads.
Do not use Templates.
They are not portable to different operating systems, especially in the way they are supported by compilers and link-editors.
The main problem raised by multiple inheritance is the ambiguity on the multiple inherited members, whether they come from two different base classes that feature members with the same name, or from the same base class that is multi-inherited. Use instead the CAA V5 Object Modeler that offers other means, such as interfaces and components, to deal with inheritance while keeping C++ single inheritance.
 |
Virtual inheritance is used in conjunction with multiple inheritance to solve the diamond ambiguity. This happens when a class inherits from two classes that themselves inherit from the same class. Since multiple inheritance shouldn't be used, virtual inheritance shouldn't be used too. |
Inheritance can be set to public, protected, or private. The following table summarizes the status of the members of the base class in the derived class, with respect to the inheritance mode.
| Inheritance mode | |||
|---|---|---|---|
| Base class member status |
public | protected | private |
| public | public | protected | private |
| protected | protected | protected | private |
| private | private | private | private |
To make sure that base class public members remain public, and that the protected ones remain protected in the derived class, always use public inheritance.
friend ClassesYou may do so if the two friend classes are conceptually one object, that is share the same life cycle. This occurs when a 'big' object has to be split in two parts. Facing this situation, consider using aggregation as an alternative technique.
If you do so, you give a direct access to your data members to any user of your class instances. This breaks encapsulation. Set your data members as private and expose methods to access them.
Static is synonymous of memory fragmentation and pagination. In addition, a static member function is required to handle a static data member. Before defining a static data member, make sure this data is really common to all instances of your class, such as an instance counter, and not only to some of them.
This will help your clients assume that these "basic" constructors always exist.
Warning: Don't do so, however, if this breaks the logic of your objects (e.g. some object absolutely requires some other object referenced in its constructor: don't provide a default constructor for them, or better provide a default constructor and an Init method to pass the initialization parameters).
For extensions: This rule is especially true for extension classes: remember, those classes are not autonomous, since they are extensions of some other classes. As a consequence, their creation is not left to their clients, because these clients never manipulate them directly. Therefore, providing a copy constructor and an assignment operator for these classes is useless and increases code size. But if you don't provide them, the C++ compiler will do it for you. To prevent this, simply declare the default constructor and the assignment operator as non virtual in the extension class private part, and do not provide their implementation. Thus, the C++ compiler will not attempt to provide their default implementation and will not attempt to allocate room for them in the virtual function table. The only thing to remember is to never call them in the extension class code.
This is important when an instance of a derived class is identified using a pointer to its base class. Assume the following:
class A
{
public :
A();
~A();
...
};
class B : public A
{
public :
B();
~B();
...
}
|
Suppose that the client handles a pointer to a B instance using the A type:
... B * pB = new B(); // Calls A(), and then calls B() A * pA = pB; ... delete pA; // Calls ~A() only ... |
When this occurs, the destructor of A is called, since pA is a pointer to A, but the destructor of B is not called, and since pA is a B object, only its A part is deleted, thus causing memory leaks. This is because the destructor of A is not virtual. If this destructor were virtual, the destructor of B would be called first, and then the destructor of A as shown below.
... B * pB = new B(); // Calls A(), and then calls B() A * pA = pB; ... delete pA; // Calls ~B(), and then calls ~A() ... |
And there is no memory leak!
Since a virtual method is intended to be overridden in a derived class, it must be accessible from this derived class. Inserting a virtual method in the private part of a class hides it from its derived classes, and from the client applications that use the class as well, and thus prevents from overriding it.
These methods are of course public or protected members of your class. For example,
class CATClass
{
public
...
virtual HRESULT ComputeUsingAGoodAlgorithm(); // Can be redefined in derived classes
HRESULT ComputeUsingMyAlgorithm(); // Cannot be redefined in derived classes
...
};
|
The methods declared as virtual can be redefined when a client application derives the class. This enables objects to be polymorphically processed and methods to be adapted to specialized objects. Because you may not, in the general case, predict who will ever derive your classes, and why, carefully set as virtual all the methods that make your class a base class and that must be redefine in the derived class. By doing so, you respect the future, by preserving the ability of possible future derivations to adapt your methods to the new objects.
Advice: Apply this rule unless you design a class not intended for derivation, because it would make your class bigger in prevision of an event that will never occur.
inline Methodsinline methods are faster than classical methods because they do
not branch to another part of the code, and consequently do not deal with all
the current data saving and restoring operations. The inline method
executable code is added at each call location by the compiler. (With a macro,
the preprocessor adds source code.) Even if it is faster, the general rule is to
avoid inline methods, because any modification to such a method
forces the client application to rebuild.
Advice: You can use inline methods only if you need
performance with a very small method. If you code large inline
methods, the inline advantage disappears. Performance analysis
should be made prior to deciding which method should be inline, and
which should not.
You must never:
inline methods
The compilers have usually trouble to implement such methods They often add an implementation of these methods in all the executable code files whose source files have included their header files, even if the class or the method is not used. This increases the size of all the modules that are client of this class.
inline default constructors
So never do this:
class MyClass : public MyParentClass
{
inline MyClass(int i) : MyParentClass(i,"WhyNot"),_MyPointer(NULL) {}
...
};
|
Constructor implementations must be put in the class source (.cpp) file.
inline methods
First, the inline advantage disappears, since calling a
method branches to another location in the executable code. Moreover, some
compilers implement such method as a static one in all executable code files
whose source files include the header file containing the inline
method. So never do this:
class MyClass
{
public :
inline int foo(int i) { return i*GetValue(); }
...
};
|
Except if it is OBVIOUS for everybody (complexes, points) .
Advice: before providing one, verify that your implementation respects their "natural" properties. For example, one would expect the addition "+" operator to be commutative. Don't provide one which is not, such as for character strings.
It is disastrous from a size perspective, and couples your code with your clients' code. They'll have to rebuild when you modify this code.
Caution: Be aware that:
class C c; |
in a header file outside a class definition IS NON declarative code, but executable code. It calls the class constructor and actually creates an instance in all the classes that include this file.
For example:
#ifndef MyClass_h
#define MyClass_h
class MyClass
{
...
};
MyClass AnInstance;
#endif
|
This code creates an instance of MyClass for each source that includes this header file, along with an initialization function called when the shared library or DLL is loaded into memory, and a destruction function called when exiting, and that often core dumps. Prefer the following declaration:
extern ExportedByCATModuleName const MyClass AnInstance; |
and insert in MyClass.cpp:
const MyClass AnInstance; |
When you pass a class instance as a method parameter or in an expression, check that its type matches the expected one, or use an explicit cast to get this type. Otherwise, the compiler attempts to implicitly cast the actual type into the required one. Some compilers issue errors when two different ways of casting exist, thus leading to an ambiguity. Some others take the casting decision for you, and don't issue an error. This is worse, since the wrong result could be detected at run time only. By explicitly casting your instance into the appropriate type, you keep control on what happens and you have knowledge of the actual conversion performed, without surprise.
For example, assume that the following class encapsulates the integer scalar type:
class MyInt
{
public :
MyInt(int iInt); // constructor
MyInt operator + (MyInt); // addition operator
operator int(); // conversion function to int
private :
int a;
};
|
The expression (x+1) is ambiguous since it can be interpreted as
either
(x.operator int() + 1) |
or
(x.operator + (MyInt(1))) |
The first way of interpretation casts x into an int before using the int addition operator to add 1, and supply the result as an int. The second way constructs a MyInt instance from the value 1, uses the MyInt addition operator to add the two MyInt instances, and leads to a MyInt instance. The same ambiguity could happen if a constructor and a conversion function could both be used to cast an object into another.
Here is the result of the compilation of such expressions:
MyInt y1 = x + 1; // error AIX, HP-UX, Windows / OK Solaris int y2 = x + 1; // error AIX, HP-UX, Windows / OK Solaris int y3 = int(x) + 1; // OK MyInt y4 = x + (MyInt(1)); // OK |
A way to make the compiler issue an error when such situations occur is to
use the explicit prefix (unknown with AIX and Solaris) for the
constructor:
class MyInt
{
public :
explicit MyInt(int iInt); // constructor
MyInt operator + (MyInt); // addition operator
operator int(); // conversion function to int
private :
int a;
};
|
The expression (x+1)may issue a compiler error.
MyInt y1 = x + 1; // error HP-UX, Windows int y2 = x + 1; // OK HP-UX, Windows int y3 = int(x) + 1; // OK MyInt y4 = x + (MyInt(1)); // error HP_UX / OK Windows |
Legal types are types you can assign to your variables. They are classified in scalar types and non-scalar types.
See also Table 3 that summarizes how to use the available types when they are used as parameters.
| char* | non-NLS character strings are defined using this header. |
| wchar_t* | Unicode character string |
| CATString | Character string encoded using the ISO 10646 code page, also known as the 7-bit ASCII |
| CATUnicodeString | Unicode character strings. CATUnicodeString must be used whenever the character string is shown to the end user as part of the user interface, and thus must be translated in the end user language. It must also be used for character strings that are not intended to be translated, but that are directly expressed in the end user language, such as file names. Use CATString or char for any other case. |
| enum |
Enumerated integer value. |
| <scalar type>[size] | Array of scalar
elements. Can be of fixed or variable size. Fixed size arrays are
defined using the * notation and not the [] notation when they are used
as out parameters (float array[]* would not be correct,
whereas float array** is).
An array of three floats will be defined as: A variable size array of floats will be defined as: |
| struct | Structure made of one or more typed fields. The type of each field is restricted to the list of authorized types defined in Table 1. |
| interface | Object Modeler interface. When the exact type of an interface is not known, the type CATBaseUnknown should be used (instead of void*). |
| CATListOf <X> | Collection class to manage different kinds of lists |
| <interface>_var | Smart pointers, also known as handlers, can be used only when a CATIA-supplied method requests one as a parameter, or returns one. Do not create new ones. |
See also Table 3 that summarizes how to use the available types when they are used as parameters.
CAA methods must use the const C++ modifier to indicate the
parameters which are not modifiable.
const can be used as follows for scalar types:
const int i; // error. i must be initialized const int j = 5; // ok const int * k; // int value can't be changed int l = 5; int * const m = &l; // m is a constant pointer, but pointed value can change const int * const n = &l; // n is a constant pointer pointed to a constant value |
This can be used with method parameters, especially for input parameters, or with returned values, and for data members that must be initialized in the constructors. Member functions can be declared as const to operate on constant objects.
::)Assume the following:
class A
{
...
virtual void m();
};
class B : public A
{
...
void m();
};
class C : public B
{
...
void f();
};
|
Do not call A::m() from C::f():
void C::f()
{
...
A::m(); // Forbidden
...
}
|
The version of the m method you execute might not fit your needs, since,
being a C instance, your class instance is also a B instance. You can either use
B::m(); or m();.
Exceptions may seem an easy and powerful way of handling exceptional situations in a given method, and possibly to deal with classical errors, by transferring the control to another part of the application that is designed to do this. It is usually the worst thing to do in large applications, since if any method can throw exceptions, any method need them to catch them. The difficulty is what to do with exceptions the method I'm currently writing is not aware of, and what could the methods that are calling it can do with the exceptions it throws. Usually, the answer is nothing, and the exception goes up in the calling stack, up to the upper level that simply aborts. Use CAA V5 errors instead.
Nevertheless, some CATIA frameworks throws exceptions, as you should use the CATTry,
CATCatch, and CATCatchOthers macros to enclose your
code that calls methods from these frameworks, and take appropriate actions when
such an exception occurs.
This set of rules deal with the lifecycle of the entities you will use.
As a general rule, any interface pointer must be:
AddRef'd as soon as it is copied
Released as soon as it is not needed any longer.A call to Release must be associated with each call to AddRef.
This rule applies as follows for method parameters:
AddRef'd an
interface pointer passed as a method in parameter. As for any in parameter,
the callee can only use the pointer, but cannot modify it, and must call
neither AddRef nor Release on this interface
pointer. The caller calls Release when the method have returned
and as soon as the interface pointer is not used any longer.
...
CATDocument * pDoc = NULL;
HRESULT rc = CATDocumentServices::New("Part", pDoc);
...
CATInit * piInitOnDoc = NULL;
rc = pDoc->QueryInterface(IID_CATInit,
(void**) &piInitOnDoc); // AddRef called by QueryInterface
...
CATInit * pInitOnDoc2 = piInitOnDoc; // pInitOnDoc is copied into pInitOnDoc2
pInitOnDoc2->AddRef(); // and immediately AddRef'd
HRESULT = pDoc->CalledMethod(pInitOnDoc2); // Use pInitOnDoc2, but don't modify it
// No call to AddRef/Release
... // Use pInitOnDoc2
pInitOnDoc2->Release(); // pInitOnDoc2 is not needed any longer
...
|
The caller passes a valued and AddRef'd CATInit
pointer to the callee that can only use the pointer, that is call CATInit
methods. The called method returns, the caller can go on using the pointer,
and Releases it as soon as it is not needed any longer.
AddRef
an interface pointer passed as a method out parameter. This interface
pointer must be passed as NULL. The possible value of the
interface pointer is of no use to the callee. The callee must call AddRef
as soon as the interface pointer is valued, and the caller must call Release.
The caller uses the interface pointer when the method has returned and calls
Release and as soon as the interface pointer is not used any
longer. This is the case, for example, when calling QueryInterface:
...
CATDocument * pDoc = NULL;
HRESULT rc = CATDocumentServices::New("Part", pDoc);
...
CATInit * pInitOnDoc = NULL;
HRESULT rc = pDoc->QueryInterface(IID_CATInit, (void**)&pInitOnDoc)
// Expanded QueryInterface
HRESULT QueryInterface(const IID& iid, void** ppv)
{
...
*ppv = ...; // pInitOnDoc is copied
*ppv->AddRef(); // and immediately AddRef'd
...
}
... // Use pInitOnDoc
pInitOnDoc->Release(); // pInitOnDoc is not needed any longer
...
|
The caller passes a NULL CATInit pointer to QueryInterface,
that values and AddRefs this pointer. The caller uses it and Releases
it as soon as it is not needed any longer.
AddRef
before passing the interface pointer. The callee can modify the interface
pointer after having calling Release, and must AddRef
the new interface pointer value. Finally, the caller must call Release
after the method returned when the interface pointer is not needed any
longer.
...
CATDocument * pDoc = NULL;
HRESULT rc = CATDocumentServices::New("Part", pDoc);
...
CATInit * piInitOnDoc = NULL;
rc = pDoc->QueryInterface(IID_CATInit,
(void**) &piInitOnDoc); // AddRef called by QueryInterface
...
CATInit * pInitOnDoc2 = piInitOnDoc; // pInitOnDoc is copied into pInitOnDoc2
pInitOnDoc2->AddRef(); // and immediately AddRef'd
HRESULT rc = pDoc->CalledMethod(&pInitOnDoc2)
// Expanded CalledMethod
HRESULT CalledMethod(CATInit ** ppv)
{
...
*ppv->Init() // Use pInitOnDoc2
...
*ppv->Release(); // Release pInitOnDoc2
*ppv = ...; // pInitOnDoc2 is revalued
*ppv->AddRef(); // and immediately AddRef'd
...
*ppv->Init() // Use again pInitOnDoc2
...
}
... // Use pInitOnDoc2
pInitOnDoc2->Release(); // pInitOnDoc2 is not needed any longer
...
|
The caller passes a copied and AddRef'd CATInit
pointer to the callee, that can use it as is before modifying its value. To
modify the interface pointer, the callee first calls Release,
copies another value in the pointer, and calls AddRef. The
interface pointer can then be used by the callee, and by the caller when the
method has returned. The caller Releases it as soon as it is
not needed any longer.
As a general rule, associate a delete with each new,
or a free with each malloc.
For out parameters:
For inout parameters, if the callee fails:
Note about CATUnicodeString: Never pass a single CATUnicodeString instance as a pointer, always use references. Also do not use pass-by-value, as this may perform string data duplication. Ideally CATUnicodeString should never be allocated on the heap (except for arrays of CATUnicodeString whose size is unknown at compile time): this class is a value type meant to be used like a native type (it performs the correct copy-on-write semantics to optimize string data sharing yet preserve the correct semantics, unlike the native char*/wchar_t* types).
NULLWhenever you create a pointer to a class instance or to an interface, always
intialize it to NULL. This ensures that the pointer doesn't take a
non-null value without you knowing, and that any part of the program uses the
pointer as if it were correctly set.
... CATBaseUnknown * piBaseUnk = NULL; ... // assign a valid value
Pointers incorrectly valued is the main memory leak source.
Whenever you use a pointer, first test its value against NULL
before using it. This ensures that the pointer has a valid value and that you
can use it safely. Otherwise, if the pointer is NULL, the pogram crashes.
...
if ( NULL != piBaseUnk )
{
... // you can use the pointer safely
}
else if ( NULL == piBaseUnk )
{
... // you cannot use the pointer
}
|
Put NULL first preferably.
Whenever you delete an object allocated using the new operator, or whenever you free a memory block allocated using either the malloc, calloc, or realloc functions, immediately set the pointer to NULL. This ensures that this pointer cannot be used any longer.
...
if ( NULL != pObject )
{
delete pObject;
pObject = NULL;
}
...
if ( NULL != pMemBlock )
{
free (pMemBlock) ;
pMemBlock = NULL;
}
...
|
Releasing an interface pointer means that you don't need it any longer, and thus that you don't intend to use it again. To ensure that this pointer will never be used afterwards, set it to NULL as soon as you release it.
... piBaseUnk->Release(); piBaseUnk = NULL; ... |
This set of rules deal with the CAA V5 Object Modeler.
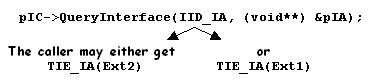
Why? To satisfy the Determinism principle. Otherwise, a call to QueryInterface for this interface is undetermined.
A call to QueryInterface must always be determinist.
Here, querying an IB pointer is undetermined. QueryInterface
returns a pointer to a TIE to IB implemented by either Ext1 or Ext2,
depending on the run time context (dictionary declaration order or
shared library or DLL loading order). There is no means for the caller
of QueryInterface to know which pointer is returned, and no
means for QueryInterface to indicate which one is returned. |
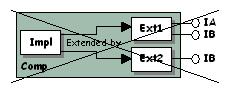 |
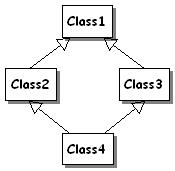
Why? To satisfy the Determinism Principle. Otherwise, a component could
implement two interfaces that OM-derive from the same interface using two
different extensions. A call to QueryInterface to get the base
interface would then be undetermined.
| Don't OM-derive IB and IC from IA. If Comp implements
IB using Ext1, and IC using Ext2, this can occur:
Why? To satisfy the Determinism Principle.
This call is undetermined. |
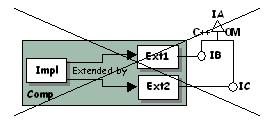 |
Do: Only C++-derive IB and IC from IA. Thus Comp
doesn't implement IA. A call to QueryInterface for IA will
return E_NOINTERFACE. How? In the cpp file of the IB and IC
interfaces, do not write:
CATImplementInterface(IB, IA); but write this instead: CATImplementInterface(IB, CATBaseUnknown); |
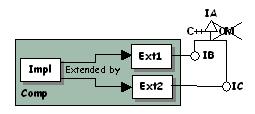 |
Do Better: Let only IA be a C++ abstract class to share method signatures, but don't make it an interface.
How? Do not include the CATDeclareInterface
macro and an IID in IA's header file, and do not provide any cpp file for IA.
Use data extensions if the extension class has data members. Otherwise, use code extensions.
Why? To save memory. The code extension is dedicated to extension without data members. A code extension class is instantiated once for all the instances of the component it belongs to, while a data extension is instantiated for each component's instance. This can save a lot of memory.
How? Declare a code extension using the CATImplementClass
macro. Like any extension class, it should always OM-derive from CATBaseUnknown.
As a code extension class, it should never C++-derive from a data extension
class.
CATImplementClass(MyExtension, CodeExtension, CATBaseUnknown, MyImplementation); |
Warning: Among other restrictions, chained TIEs can't be used with code extensions.
Why? If you set another class instead of CATBaseUnknown, such as the class from which the extension class C++-derives, you introduce an unnecessary additional node in the metaobject chain that can only decrease performance.
How? This is done using the CATImplementClass
macro with CATBaseUnknown or CATNull always
set as the third argument.
CATImplementClass(MyExtension, DataExtension, CATBaseUnknown, MyImplementation); |
or
CATImplementClass(MyExtension, DataExtension, CATNull,
MyImplementation);
Why? If you create an extension that C++-derives from another extension that itself implements several interfaces, you may instantiate useless objects. You or your component's clients might use methods of an inherited interface not explicitly implemented by your component, but whose bodies come from the inherited extension. As a result, your extension may have undesirable companion objects, and any client can get a pointer to an interface implemented by these companion objects.
For example, suppose that you create Ext2 that implements IB for component Comp2. Ext2 derives from Ext1 that implements IA and IB, but IA is of no use to you. Object Modeler inheritance makes Comp2 implement also IA, but you have not included a TIE macro for IA. Everything is OK with IB, but assume that a client already has a pointer to IC, and queries a pointer to IA.
 |
 |
Instead of getting a pointer to a TIE_IA on Ext2, as expected, the client gets it on a new instance of Ext1, even if the dictionary is correctly filled in, that is, even if Impl2 declares that it implements IA. This means that in addition to Ext1 instantiated as the base object for Ext2, that is (Ext1 *) Ext2, another instance of Ext1 is created by QueryInterface, and is pointed to by the returned TIE_IA. The major problems are:
There are three solutions.
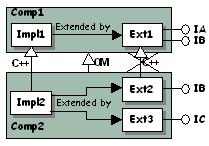 |
1. The recommended solution: Define and use only unit interfaces, that is, interfaces that expose methods that must ALL be implemented. In this case, there is no need to C++-derive Ext2 from Ext1. |
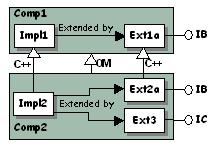 |
2. Otherwise, if you need to derive from an extension that implements IB, choose one that implements ONLY IB. Ext2a C++-derives from Ext1a, includes a TIE_IB macro, and the interface dictionary contains the IB declaration for Impl2. |
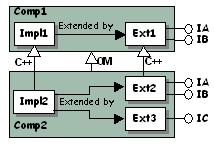 |
3. If you really can't do anything else, declare all the interfaces whose implementations are inherited by Ext2 from Ext1. To do this, include a TIE macro for IA and IB to Ext2, and correctly fill in the interface dictionary. |
QueryInterfaceTo correctly use QueryInterface:
NULL
QueryInterface
SUCCEEDED and FAILED.
The output parameters of functions such as QueryInterface are
valid and usable if and only if SUCCEEDED returns TRUE.
Never test the output pointers. Always test the HRESULT value using SUCCEEDED
before using the output pointers.
Smart interface pointers raise more problems than they solve.
You will need sometimes to make interface pointers and smart pointers coexist, because, for example, you call a function that returns an interface pointer you need to cast into a smart pointer to call another function. Here are the rules to smooth over this coexistence.
...
{
CATIXX_var spCATIXX = ::ReturnAPointerToCATIXX();
if (NULL_var != spCATIXX)
{
spCATIXX->Release(); // Release the returned interface
// pointer using spCATIXX
... // Use spCATIXX
}
...
} // spCATIXX is released
|
The reference count is incremented by the global function, and
incremented again by the assignment operator redefined by the smart pointer
class. That is once too often. To decrement the reference count, you can't
use the returned interface pointer since you have no variable to handle it.
You must then use the smart pointer spCATIXX. The count decrements. When
going out of scope, the smart interface pointer is deleted and the count
decrements again. Avoid doing that. Even if this is correct, you can
easily skip from this case to the next one. Do this instead.
...
{
CATIXX * pCATIXX = ::ReturnAPointerToCATIXX();
if (NULL != pCATIXX)
{
CATIXX_var spCATIXX = pCATIXX;
pCATIXX->Release(); // Release the returned interface pointer
if (NULL_var != spCATIXX)
{
... // Use spCATIXX
}
} // spCATIXX is released
...
}
|
CATIYY_var spCATIYY = ::ReturnAPointerToCATIXX(); |
You have cast the returned CATIXX pointer to a smart pointer to CATIYY. This returned pointer to CATIXX couldn't be released, since you have no variable to handle it. The reference count will never reach 0, and the component will never be deleted. Never do that. Do this instead.
CATIXX * pCATIXX = ::ReturnAPointerToCATIXX(); CATIYY_var spCATIYY = pCATIXX; pCATIXX->Release(); |
CATIXX * pCATIXX = SmartPtrToCATIXX;
This is not smart, and you must call AddRef and Release on the interface pointer.
CATIXX * pCATIXX = ::ReturnASmartPtrToCATIXX(); |
The returned smart pointer is a volatile variable. This makes a core dump with unchained TIEs, or with any TIE if the returned smart pointer is the only handle on to the component.
To correctly fill in the interface dictionary, follow the two rules below:
A component must not declare the interfaces whose implementations are OM-inherited through OM component inheritance.
Why? To satisfy the Determinism Principle. Depending on the run
time context, that is, which shared libraries or DLLs are loaded in memory, and
on other interface dictionary declarations, QueryInterface may find
a pointer to the requested interface on an inherited implementation or
extension, and not on the current one.
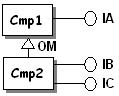 |
No need to declare IA for Cmp2. The dictionary must only include
Cmp1 IA LibCmp1 Cmp2 IB LibCmp2 Cmp2 IC LibCmp2 |
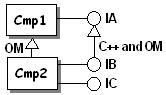 |
For example, when IB C++- and OM-derives from IA:
Cmp1 IA LibCmp1 Cmp2 IA LibTIE_IBCmp2 Cmp2 IB LibCmp2 Cmp2 IC LibCmp2 |
| [1] | CAA V5 C++ Naming Rules |
[Top]
| Version: 1.0 [Jan 2000] | Document created |
| [Top] | |
Copyright © 2000, Dassault Systèmes. All rights reserved.